작성자 : 최정인 (K-DEVCON DAEJEON 매니저)
안녕하세요~ K-DEVCON(k-devcon.com) 입니다. 😊
지난 포스팅에 이어 < 데브콘 대전 : 이월엔 지오! > 행사의 2부 포스팅을 시작하겠습니다.
혹시 <데브콘 대전 : 이월엔 지오! > 행사 1부가 궁금하신 분은 이 링크를 통해 확인하실 수 있습니다!
[행사 장소]
<데브콘 대전 : 이월엔 지오!> 의 행사 장소였던 SV - GROUND 입니다 :>
이쯤되니 SV - GROUND의 홍보대사라 해도 되지 않을까 싶습니다.
마침 이번 행사를 마치고서 SV - GROUND 관계자분에게 기분좋은 문자가 왔었다고 하는데요. 매번 깨끗이 사용하고, 정리도 잘 해주셔서 감사하다는 말을 하셨다고 합니다. 이는 운영자분들의 노고뿐만 아니라, 우리 K-DEVCON 행사에 참석하신 분들도 협조해주셨기 때문이란 생각이 듭니다. 😊


행사 스케줄은 다음과 같습니다 :)
 |
이제 <데브콘 대전 : 이월은 지오!> 행사 2부 시작해보겠습니다~
두번째 세션 : 공간정보 BI에 LLM같은걸 끼얹나
두번째 세션의 주제는 [공간정보 BI에 LLM같은걸 끼얹나]였습니다.
이번 세션은 엡실론델타의 대표이자, 클라우드메이트의 엔지니어로 재직중이신 윤성국님께서 진행해주셨습니다. 😊

윤성국님은 GIS 개발자의 일보단, 주로 AI 엔지니어 분야의 일을 하셨다고 하는데요. 이러한 경력을 인정받아, 윤성국님은 입사한지 일주일이 되기도 전에 회사의 공간정보BI 프로젝트 관련 회의에 참여하게 되었다고 합니다.
이번 세션의 주제는 바로 그 프로젝트를 완료하기까지의 (길고 험난했던) 여정에 대한 것이었습니다.

프로젝트의 의의는 회사의 서비스(Carto)의 한국영업을 위해 고객사에 보여줄 Demo를 만드는 것이었는데요.
예를 들어, 아래 사진처럼 검색어 입력란에 "강남에서 가장 비싼 곳을 알려줘."라고 질문을 하면 그 결과를 지도에 표시해주는 것입니다.
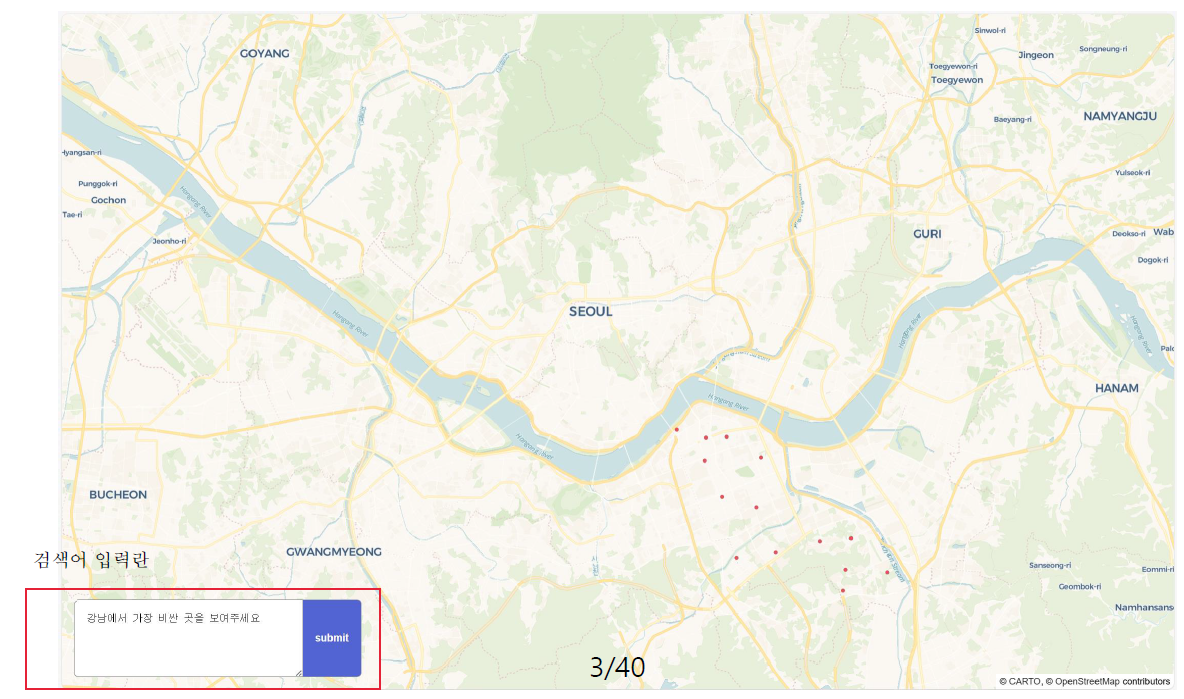
성국님은 오늘 발표를 위해 그 데모 프로그램을 직접 보여주셨습니다. 질문을 입력하기만 하면 사람이 직접 지도를 보며 일일이 부동산 정보를 확인하지 않아도 원하는 결과를 찾아서 보여준다니, 너무나 유용한것 같습니다.😊
다만 이 유용한 데모를 만들기까지 과정은 쉽지 않았다고 하시는데요.
그 과정은 다음과 같았습니다.
1. 데이터 탐색
2. 데이터 전처리
3. BigQuery
4. 데모 프로그램 제작
5. 사용성 개선

[1. 데이터 탐색]
'고객사에 보여줄 Demo 만들기'에 대해 회의하면서 사람들의 다채롭고 개성적인 아이디어를 들으시던 윤성국님은 직접 데이터 탐색에 나서 거의 700여건의 데이터를 확인하셨다고 합니다.
그렇게 최종적으로 결정한 데이터는 1) 부동산실거래가데이터, 2) 서울시골목상권분석데이터였습니다.

[2. 데이터 전처리]
이러한 데이터는 곧바로 사용할 수 없기 때문에 전처리하는 과정이 필요하다고 하셨는데요.
두가지 작업을 해야했다고 하셨습니다.
1. 텍스트 형태의 주소를 좌표로 변환.
지도에 표시해야 하므로, 텍스트 주소를 좌표로 변환하는 작업이 필요합니다.
2. 좌표계를 적절한 좌표로 변환.
종종 공공데이터에서는 대한민국의 좌표가 잘못표시된 경우가 있는데, 그런 것들을 정리하는 과정입니다.
아무래도 지리공간과 관련된 데이터이다보니 좌표에 대한 전처리 과정이 필수인것 같습니다.

[3. BigQuery]
이렇게 (고생고생하며) 데이터를 탐색하고 전처리한 것은 결국 BigQuery를 위한 준비과정이었던것 같습니다.
참고로, BigQuery란 클라우드 환경에서 데이터를 편리하게 관리하고 분석할 수 있게 해주는 데이터 웨어하우스인데요. 머신러닝, 지리정보 분석, BI같은 기능을 제공하며, 많은 양의 데이터를 SQL문을 통해 빠르게 분석할 수 있다고 합니다. 다만 SQL문을 사용하기 때문에 데이터 타입에 몹시 신경을 써야할 것 같은 느낌이 듭니다.
특히 지리정보는 공간을 특정해야하기 때문에 일반적인 데이터와 형식이 조금 다를것 같은데요.
이렇게 지리정보에 특화된 데이터 타입으로 GeoJSON이란 것이 있습니다.

Geo(지리정보)와 JSON이 결합된 GeoJSON은 위 이미지와 같은 형식을 따르며, point(좌표)를 가지고 있습니다.

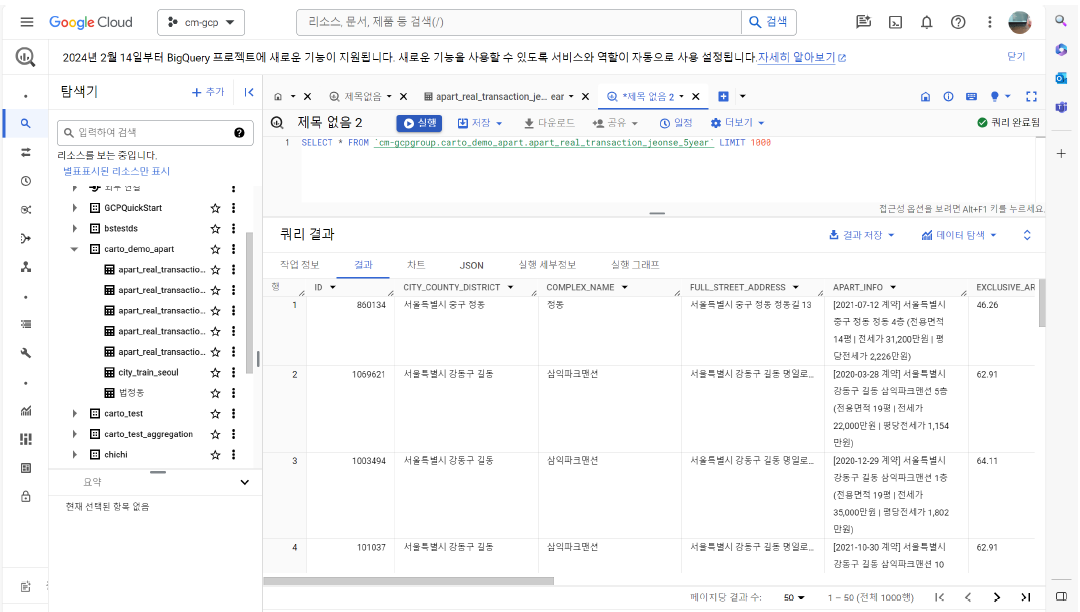
이렇게 데이터 타입까지 적절히 맞춘 후 SQL문을 날리면, 아래 그림처럼 퀴리 결과를 보여준다고 합니다.(예시입니다!)
[4. 데모 프로그램 제작]
(놀랍게도,) 지금까지의 과정은 그저 프로젝트의 사전작업에 불과하였습니다.
프로젝트의 목적이 " 회사의 서비스(Carto)의 한국영업을 위해 고객사에 보여줄 Demo를 만드는 것"이었으니, 이제까지 작업했던 BigQuery와 회사의 서비스(Carto)를 연동하는 작업이 필요합니다.
이 작업은 비교적 쉽다고 하시는데요. Carto 서비스에서 이미 BigQuery를 연동할 수 있는 기능을 제공하고 있다고 합니다.
Carto 의 작업공간에서 BigQuery를 연동한 후, Map을 제작하고, Widgets을 만들고, Interaction을 설정하면 된다고 합니다..!
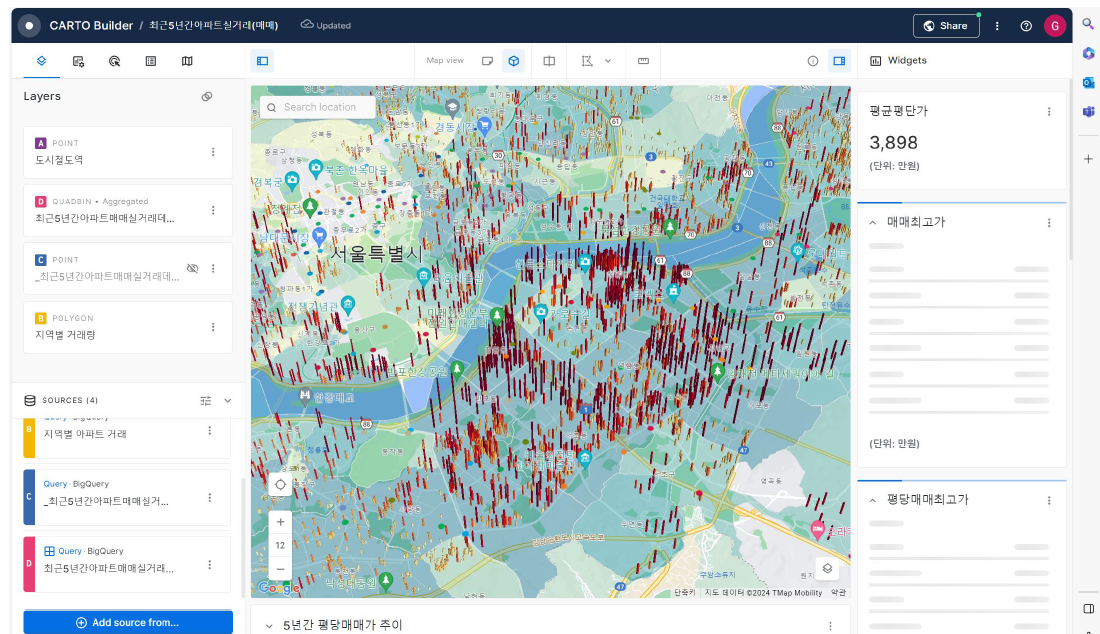
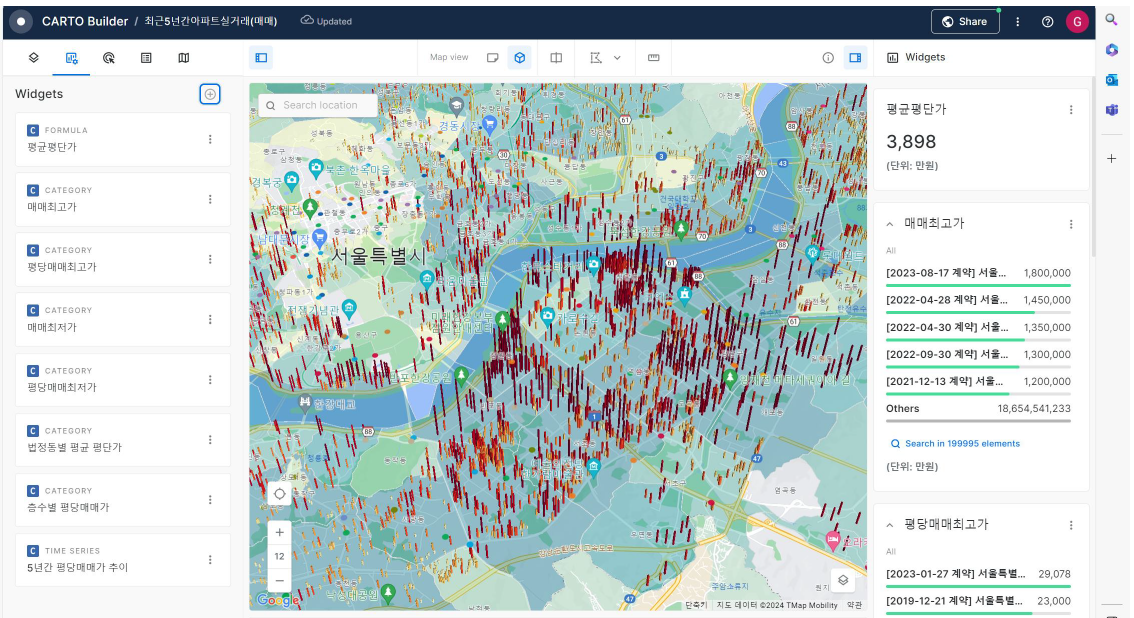
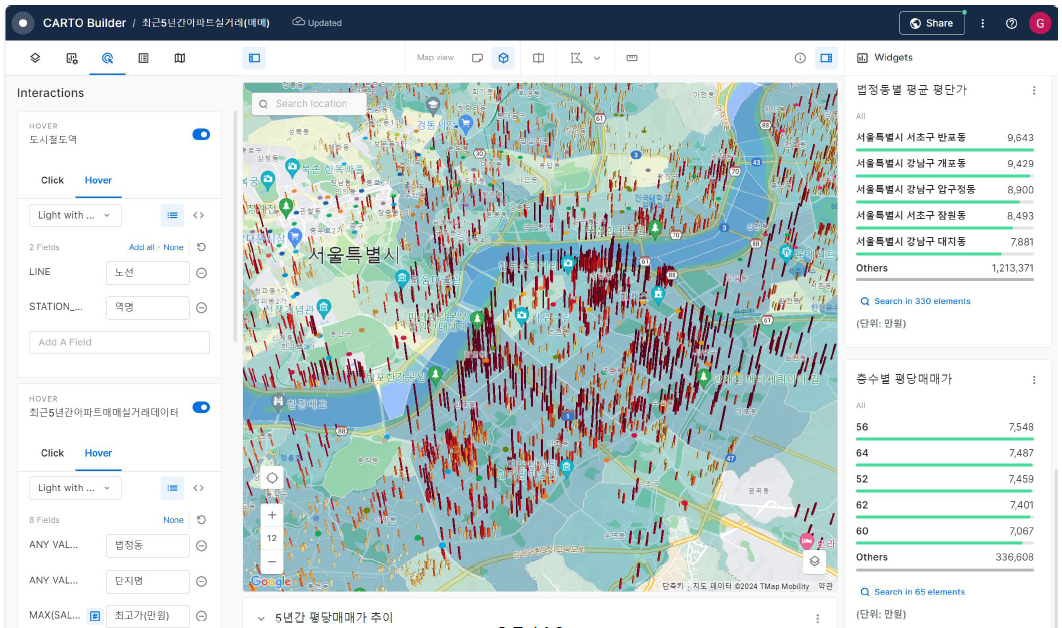

이제 BigQuery와 Carto를 연동하는 작업도 끝났고, 원하는 데모 프로그램이 만들어졌으니 프로젝트 끝!이라면 참 좋았겠으나, 다음과 같은 불편함이 남아있었다고 합니다.
1. Layer와 SQL이 1대1 맵핑상태이므로 새로운 Layer를 만들기 위해서 사람이 SQL을 일일이 만들어야 함.
2. 의사결정권자가 해당 BI 를 수정하기 위해서는 개발자가 필요함.
3. 의사결정권자가 BI 수정 지시 후 작업완료까지 많은 시간 소요됨.
1번 문제의 불편함은 당연하지만, 2번과 3번에 대한 불편함도 실무환경에서는 무시할 수 없는 문제인 것 같습니다.🤔

이러한 불편함은 결국 사용성을 개선해야한다는 귀결로 이어질 수밖에 없었는데요.
성국님은 '어떻게 개선해야할까'에 대해 아주 많은 고민이 있었다고 합니다.

[ 5. 사용성 개선 ]
어떤 일이든 무언가를 개선하기 위해서는 먼저 불편함의 원인을 파악하고, 현실적으로 수행이 가능한 방안을 찾아야 할 것입니다. 예를 들면, 수정사항이 있을 때마다 의사결정권자가 개발자를 부르는 것이 불편하다하여 의사결정권자에게 '간단합니다' 라고하여 SQL 및 코드짜는 법을 알려주는 것은 너무나 비현실적일 것입니다.
최종적으로, 성국님이 사용성 개선을 위해서 생각한 방안은 AI를 이용하는 것이었는데요.
그 해결 과정이 재미있었습니다.
[개선 전]

Carto 서비스에서 지도를 그리는 과정은 위의 이미지처럼 사람이 SQL을 작성하고, BigQuery를 이용하고, Query 결과가 Carto 에 반영되는 방식이었는데요. 그러다보니 사람이 일일이 SQL을 수정해야했습니다.
성국님은 이 부분에서 사람대신 SQL을 수정할 수 있는 방법이 있으면 좋겠다는 생각에 AI 를 활용하게 되었다고 합니다.
[개선]
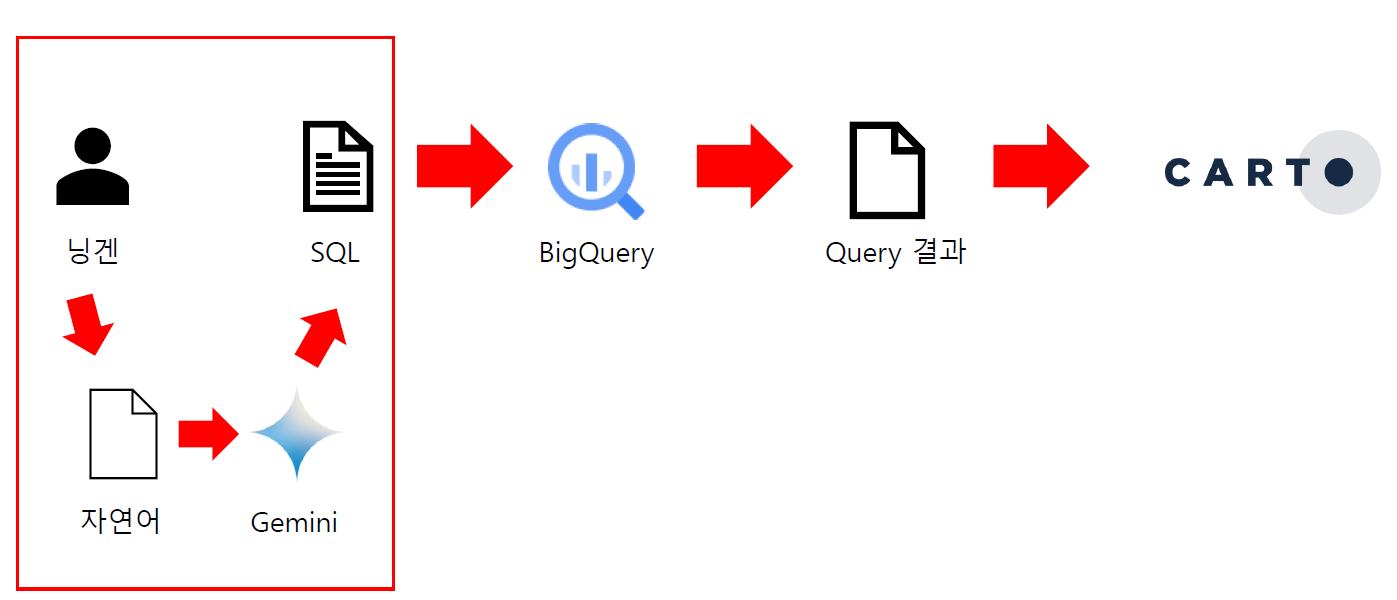
즉, 사람이 익숙한 자연어로 질문을 하면 AI가 알아서 적절한 SQL을 만들어주는 것이죠. (원리는 모릅니다)

혹시 생산형 AI 에 대해 들어보셨나요?
ChatGPT가 대표적인 생산형 AI인데요. Input을 제공하면 스스로 학습한 결과를 Output합니다.
이러한 인공지능이 유명해지면서 생겨난 직업이 프롬프트 엔지니어입니다. 프롬프트 엔지니어의 일은 ChatGPT와 같은 대규모 언어 모델(Large Language Model, LLM)에서 원하는 결과를 얻기 위해 프롬프트를 만들고 최적화하는 것인데요. ChatGPT 를 사용해 보신분은 아시겠지만, 생성형 AI가 항상 사용자가 의도한 답변을 출력해주진 않습니다.
그렇기 때문에 성국님 역시 AI가 엉뚱한 결과물을 출력하지 않도록 프롬프트 최적화 작업을 해야하셨다고 합니다.

성국님의 설명을 들어도 잘 모르겠는 단어가 이때 등장했었는데, 바로 임베딩과 시멘틱서치에 대한 개념이었습니다.
딥러닝은 주어진 입력(데이터)에 대해 원하는 출력이 나오도록 스스로 유의미한 값을 찾아 학습합니다.
그러한 딥러닝 모델 중 하나인 LLM은 주어진 입력(데이터)이 자연어이기 때문에, 텍스트 문장에 포함된 여러개의 단어를 적절한 가중치로 스스로 학습하는데요. 가령 LLM 모델에게 "영화 리뷰 중 긍정적인 리뷰만 알려줘."라고 했을 때, '재밌었다'라는 워딩과 '또 보고싶다' 라는 워딩은 표장은 다르지만, 유사도가 있다는 것을 알도록 학습되어야 해야합니다.
LLM 모델은 이처럼 서로 다른 개체(혹은 문장 등)가 유사한 것인지, 다른 것인지 판단하는 것이 매우 중요한데요. 모델에 임베딩을 적용하면 어떤 단어에 어느 정도의 가중치를 줄지 스스로 학습하여 벡터 형식의 수치로 나타냅니다.
이 임베딩 벡터값이 중요한 이유는, 이 수치를 적절히 학습해야만 AI가 사용자가 원하는 검색 결과를 제시할 수 있기 때문입니다.
한편,
시멘틱 서치(Semantic Search )는 검색 쿼리가 키워드를 찾는 것뿐만 아니라 사용자의 검색 의도를 파악하고, 문서에 기술된 어휘의 의미와 문맥을 분석하여, 사용자가 원하는 검색 결과를 제시하는 것을 뜻합니다. 여기서 유사도가 높은지 낮은지를 판단하기 위해 임베딩 벡터가 활용된다고 합니다.

성국님은 이러한 지식을 바탕으로 프롬프트 최적화 작업을 하셨는데요. 다만 그 방법은 경험의 누적과 노하우가 필요하다고 합니다.
사실, 세션을 들으면서 프롬프트 최적화 작업을 하는데, 왜 임베딩과 시멘틱서치의 개념까지 파고들어야 했을까 하는 의문이 있었는데요. 성국님의 마지막 인사에 말이 참으로 인상이 깊었습니다.

여기까지가 성국님이 프로젝트에 참여하여 서비스를 개선하기까지의 과정이었습니다. 실무의 생생함을 그대로 느낄 수 있어서 매우 재밌는 시간이었습니다. 😊
여기까지 <데브콘 대전 : 이월엔 지오!> 행사 2부에 대한 이야기를 적어보았습니다.
다음 < 데브콘 대전 : 이월엔 지오!> 행사 3부를 기대해주세요~
(나가시기 전, 데브콘 블로그 구독 꾸욱 ~ 잊지마세요! 😎)
K-DEVCON은 IT 전문가 커뮤니티 그룹으로 다양한 IT 기술을 연구하며 회원간의 소통을 공유하는 모임 입니다. 현재 IT업계에 종사하고 있거나, 종사할 예정이거나, IT를 공부하는 학생 그리고 IT에 관심이 있다면 누구나 함께할 수 있습니다.
기술 세미나, 스터디, 토론 등 다양한 활동을 하고 있으며, 주요 소통 및 이벤트 공유는 오픈챗 및 홈페이지 등을 통해서 공유하고 있습니다.
소프트웨어 엔지니어, 데이터 엔지니어, 머신러닝 엔지니어, 시스템 엔지니어, 시큐리티 엔지니어, 데브옵스, SRE, PM, Educator, UI/UX, 스타트업, 대학생 등 다양한 구성원이 활동 중입니다.
homepage : https://k-devcon.com
contact : info@k-devcon.com
'데브콘 행사 후기' 카테고리의 다른 글
| [Review] 2024-03-23 K-DEVCON Deajeon : 삼월엔 데이터! (1) (0) | 2024.03.31 |
|---|---|
| [Review] 2024-02-24 K-DEVCON Deajeon : 이월엔 지오! (3) (0) | 2024.03.23 |
| [Review] 2024-02-24 K-DEVCON Deajeon : 이월엔 지오! (1) (1) | 2024.03.06 |
| [Review] 2024-02-22(목) K-DEVCON 서울 : 이월엔 그로스! 2부 (0) | 2024.02.29 |
| [Review] 2024-02-22(목) K-DEVCON 서울 : 이월엔 그로스! 1부 (0) | 2024.02.27 |